As promised in my last post here's a blog post about the QNIBTerminal powered SLURM stack with auto generated dashboards. I started writing it two weeks ago, embarrassing - sorry for the delay. As a reminder I'll keep the date.
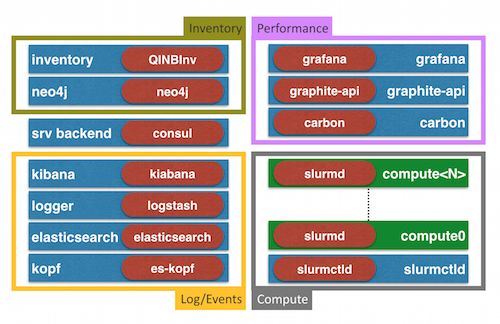
The stack looks like this:
For those following my blog most of the stack should look familiar.
Since I was ask on hub.docker.com if my qnib/elk image is going to provide kibana4 in the near future I figured it would be worth to blog about it.
The image in question is quite nice for trying the ELK stack out and I take some pride in stating that it's the number 2 image popping up if you search for 'elasticsearch' (and rank by stars). :)
I talked about QNIBTerminal and what I am working on; connecting dots between metrics (graphite-ecosystem), logs (logstash & friends), inventory (QNIBInventory based on a GraphDB) and SLURM (cluster resource scheduler). I put it up on youtube:
Since I was asked (thanks Dmitry) via mail how to setup QNIBTerminal to run MPI jobs, I created a REAMDE within the qnib/compute repository, but why not put it in a blog post (README.md is Markdown, my blog is Markdown...)?
The foundation of QNIBTerminal is an image that holds consul and glues everything together. I used the Easter break to refine my qnib/slurm images - this blog post give a quick intro.
I had consul on my list for some time, but it was just recently that I gave it a spin. And I must admit I am
hooked. It provides a nice set of functionalities that I need to bootstrap...
Let's give a quick ride by starting two containers: server and client
Apart from the fact that it's always a pleasure to talk to HPC enthusasts like Rich, it was a perfect oportunity to record the slides,
since I failed to operate the GoPro and my MacBook Pro propperly. IMHO the recording was even better then the original.
For starters I added a MPI Microbenchmark, which provides a nice bare MPI flavor.
On my way back from the 'HPC Advisory Council (HPCAC) China Workshop 2014' it is about time to wrap up my (rather short) trip.
I was presenting my follow-up on docker in HPC. At the ISC14 this summer I talked about the HPC cluster stack side; thus,
how to encapsulate the different parts of the cluster stack to shift to a more commoditized one.
As I was interviewed by Rich about this he was continiously asking how this will impact the compute virtualization.
My mockup was spawning some compute nodes, but they are not distributed, but sitting ontop of one (pretty)
oversubscribed node. Running real workloads was not my intention...
Long story short: 'Challange accepted' was what I was thinking.
If you are looking for an excuse to use logstash your local webserver is low hanging fruit.
Someone accesses your website and your web server will store some details about the visit:
10.10.0.1--[29/Oct/2014:18:42:18+0100]"GET / HTTP/1.1"2002740"-""Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4"10.10.0.1--[29/Oct/2014:18:42:19+0100]"GET /css/main.css HTTP/1.1"2002805"http://qnib.org/""Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4"10.10.0.1--[29/Oct/2014:18:42:19+0100]"GET /pics/second_strike_trans.png HTTP/1.1"20029636"http://qnib.org/""Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4"
At the ISC14 Christian had an interview with Rich Brueckner from insideHPC about his QNIBTerminal BoF-Session.
Slides of the talk could be found in this post.
At ISC14 I gave a Birds-of-the-Feather talk about the benefits provided by overlaying multiple information layers
within the HPC cluster stack. The topic debuted at OSDC14 (post with video here).
Furthermore I had an video-taped interview with Rich Brueckner from insideHPC, which is available here.
Yesterday I pimped the way to build the cluster; now it is time to start the beast.
For now it is a simple bash function; there must be a smarter way... fabfile, I heard... :)
In my previous post I described what drove me to give docker a spin and create a
virtual HPC cluster stack.
This post provides a step by step guide to run a basic QNIBTerminal with four nodes.
To get this one going there is no need for a lot of horsepower. I ran it on a 3-core AMD
machine from back in the days. Even a VM should be able to lift it.
On my way home (at least to an intermediate stop at my mothers) from the
OSDC2014 I guess it's time to recap the last couple of weeks.
I gave a talk which title reads 'Understand your data-center by overlaying multiple information layers'.
The pain-point I had in mind when I submitted the talk was my SysOps days debugging an InfiniBand problem that was connected to
other layers of the stack we were dealing with. After being frustrated about it I choose to use my BSc-thesis to tackle this problem.
The outcome was a not-scaling OpenSM plug-in to monitor InfiniBand. :)
But the basics were not as bad, so I revisited the topic with some state-of-the-art log management (logstash) and
performance measurement (graphite) experience I gained over the last couple of month.
Et voila, it scales better...
At the OSDC14 in Berlin Christian debuted with QNIBTerminal, a framework to spin up a complete cluster software stack.
The talk was about overlaying multiple information layers to correlate metrics and events throughout the cluster stack.