HPCAC China 2014: 'Containerized MPI workloads'
On my way back from the 'HPC Advisory Council (HPCAC) China Workshop 2014' it is about time to wrap up my (rather short) trip.
I was presenting my follow-up on docker in HPC. At the ISC14 this summer I talked about the HPC cluster stack side; thus, how to encapsulate the different parts of the cluster stack to shift to a more commoditized one.
As I was interviewed by Rich about this he was continiously asking how this will impact the compute virtualization. My mockup was spawning some compute nodes, but they are not distributed, but sitting ontop of one (pretty) oversubscribed node. Running real workloads was not my intention...
Long story short: 'Challange accepted' was what I was thinking.
TL;DR An interview with Rich of insideHPC was recorded as an aftermath.
I got myself access to a small 8 node cluster under the hood of the 'HPC Advisory Council' and started to deploy containers. To make it more convenient I used the SLURM resource scheduler. Thus, I am able to submit the benchmarks to the group of nodes and SLURM will take care about the scheduling.
Testbed
This is how it looks like. The native system is installed with CentOS 7. It has to be noted that it is a pre-release version. But since I was aiming to be as close to RedHat Enterprise Linux (RHEL) 7 as possible, this was the obvious choice.
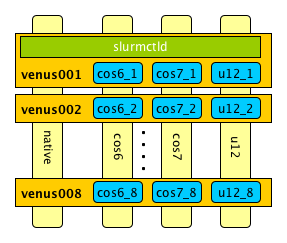 |
Why RHEL7?
|
HPCG
First I ran the HPCG Benchmark, which mimics a thermodynamic application workload.
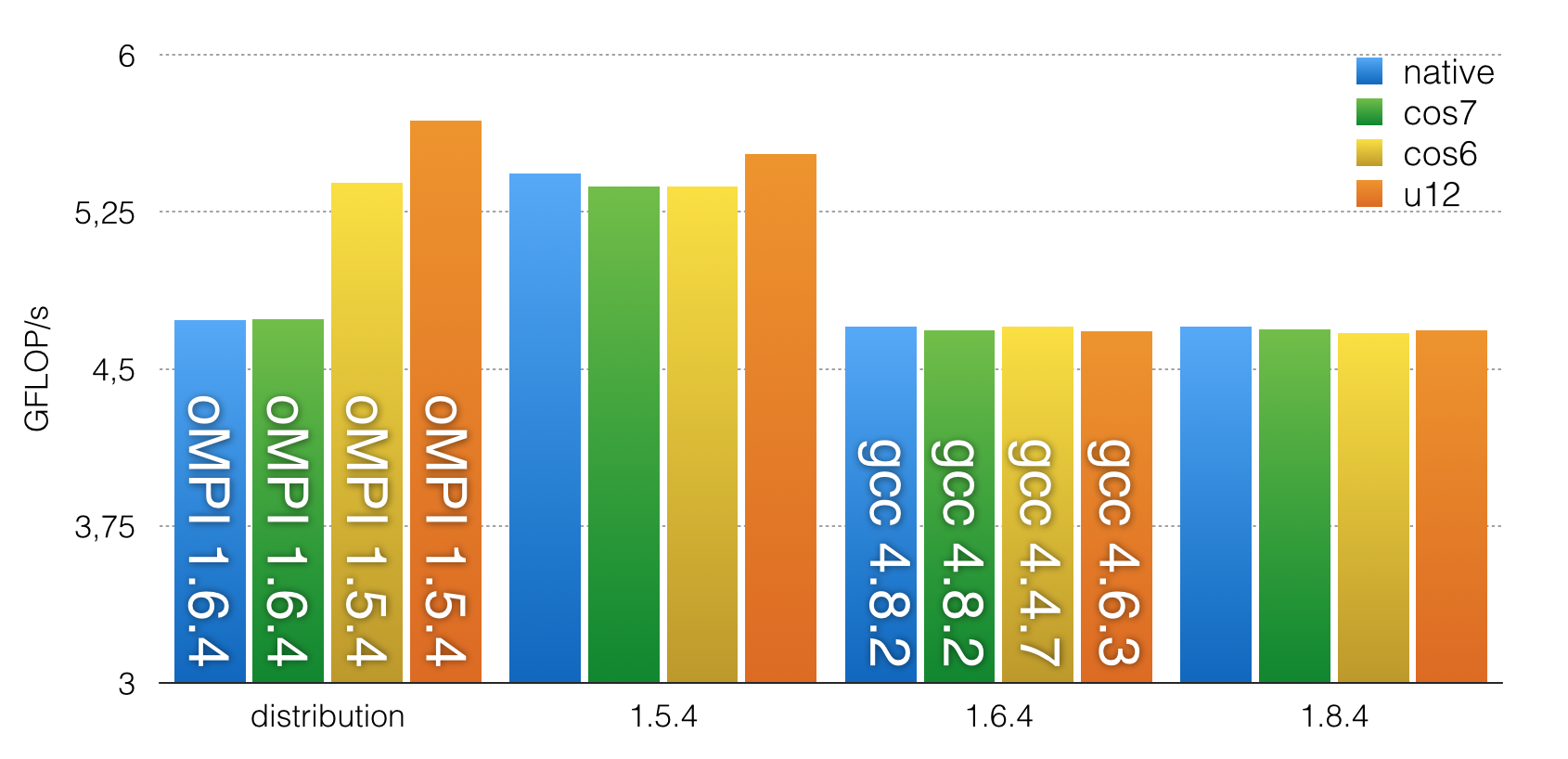
OK, let this trickle down a minute... What are we looking at?
Comparing CentOS 7 on bare-metal and within a container the performance is quite similar. That's kind of what I expected. By comparing Open MPI >=1.6.4 the performance is also what everyone would expect. But how about the 1.5.4 performance? Ubuntu12 is outperforming the native host.
OSU MPI Micro Benchmark
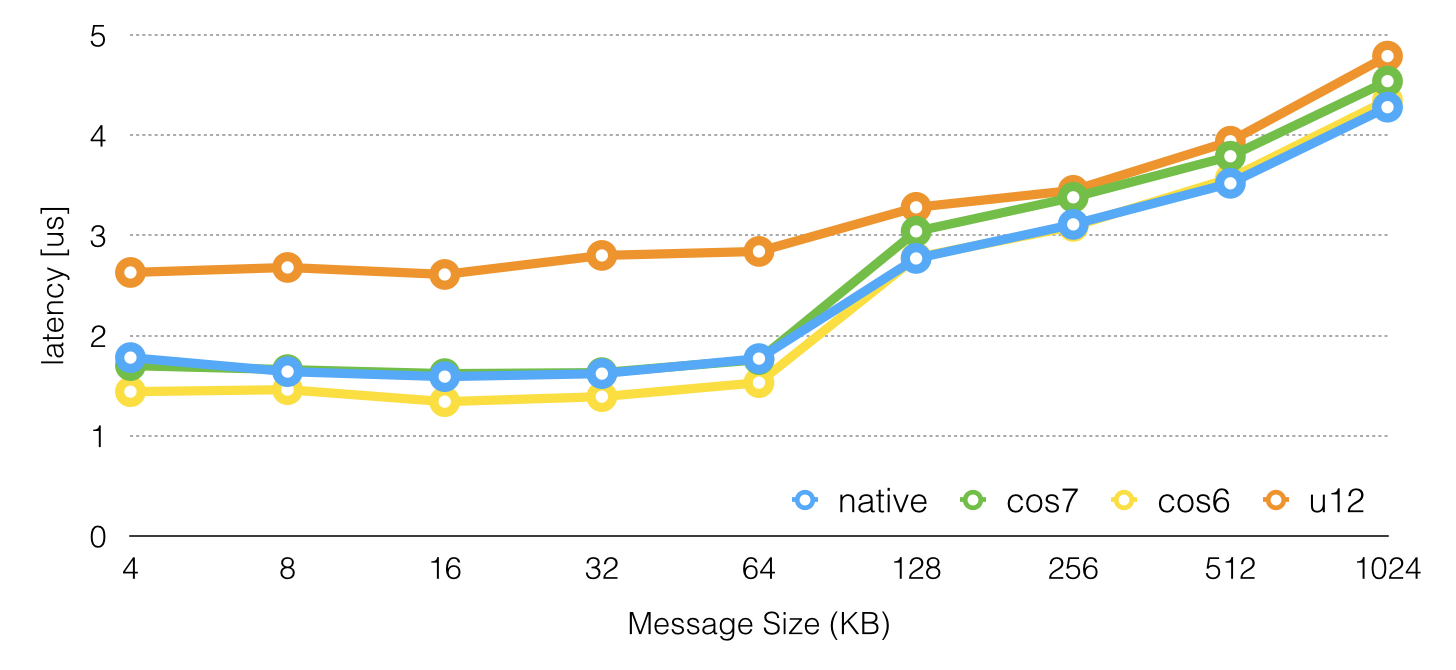
To check against other evaluations the OSU MPI Benchmark is used.
$ mpirun -np 2 -H venus001,venus002 $(pwd)/osu_alltoall
# OSU MPI All-to-All Personalized Exchange Latency Test v4.4.1
# Size Avg Latency(us)
1 1.83
2 1.82
4 1.74
8 1.63
16 1.62
32 1.68
...
The distributions Open MPI version shows simmilar performance among the RHEL derivates and ubuntu struggeling.
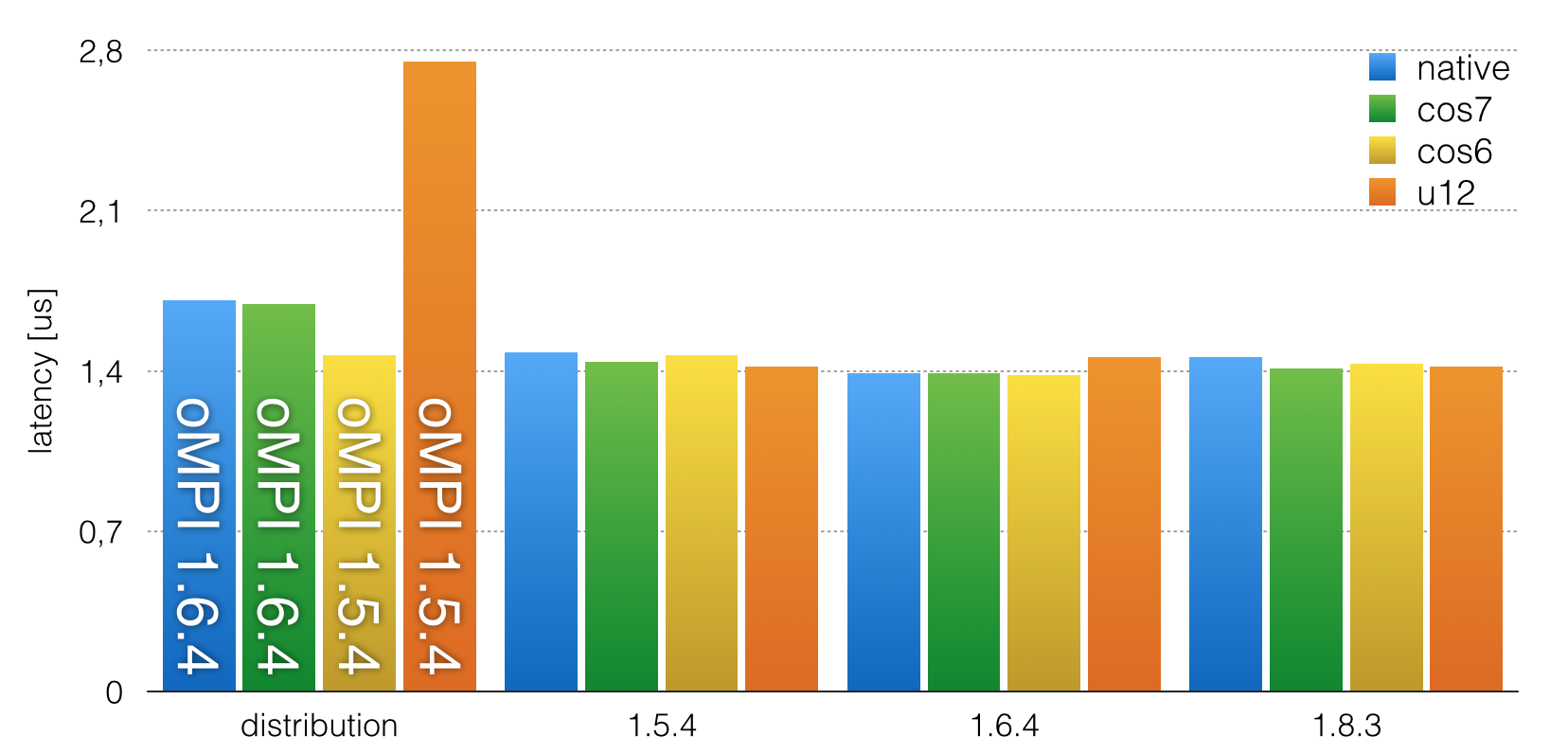
To compare the mpi versions I build an average over the 2digit msg size, since they are in the same ball-park anyway. I am using an ugly bash hack, current position is the Moscovien Airport and it's late:
$ cat avg_2dig.sh
function doavg {
echo "scale=2;($(echo $*|sed -e 's/ /+/g'))/$#"|bc
}
function avg2dig() {
val=$(cat $1|egrep "^[0-9][0-9]?\s+[0-9\.]+$"|awk '{print $2}'|xargs)
if [ "X${val}" != "X" ];then
doavg ${val}
fi
}
$ for x in $(find job_results/mpi/ -name osu_alltoall.out|xargs);do echo -n "$x -> ";avg2dig $x;done|grep 1.8.3
job_results/mpi/venus/omp-1.8.3/2014-11-06_22-03-59/osu_alltoall.out -> 1.46
job_results/mpi/centos/7/omp-1.8.3/2014-11-06_22-05-33/osu_alltoall.out -> 1.41
job_results/mpi/centos/6/omp-1.8.3/2014-11-06_22-05-45/osu_alltoall.out -> 1.43
job_results/mpi/ubuntu/12/omp-1.8.3/2014-11-06_22-07-02/osu_alltoall.out -> 1.42
Doing so the result is shown below.
Future Work
Different native installation
Next I would like to install Ubuntu12 as a native system to check whether the performance changes among the different hosts. Idealy the native performance is a little bit higher then the one given by the Ubuntu12 container and the performance of the rest of the bunch stays the same. That would imply that the performance of the kernel used in Ubuntu12 is similar to the one in CentOS 7. I am curious how this plays out.
SV-IOR (hardware IO virtualization)
If I use the current setup the performance is going to plunge if two containers are concurrently using the IB hardware. The reason for that should be found in the concurrent DMA access from all of them, without knowing what they are doing.
SV-IOR should come to the rescue here, by providing different DMA domains via distinct virtual devices. When activated, a kernel parameter is given to state how many devices should be created. Instead of having only one IB device there are many. The network adapter will take care of the 'multiplexing'. The promise is going to be that two partitions could run a benchmark concurrently without much penalty.
Security evaluation
As I am a practical guy, the first thing I did in this benchmark is to disable the firewall and SELinux. Yeah, I know... How dare I!
In the early docker days (not sure if we are out yet) security was explicitly no concern. If you are able to communicate with the server socket, you are basically root in all containers and since you can mount the host systems file system as root you are able to mess up a lot.
If it is used on an HPC system the question might be if security is much of a concern compared to the hyperscale web-startup type of usage. IMHO they should come up with something and the HPC community chooses what ever fits best. But this has to be discovered some day...
Benchmark real-world applications
Using an MPI Benchmark and HPCG is simply not enough. Different workloads should be checked out.
Conclusion
As far as this study is concerned docker has shown very promissing results. Out-of-the box a container with a stabelized userland (CentOS 6, Ubuntu 12) is able to beat the performance of the native machine. Granted, that the bare-metal installation has the disadvantage of being a beta version without much optimization and bugfixing done, but this is somehow what I intended to show in the first place.
The bare-metal installation could be bleeding edge to provide the latest and greatest kernel features and the conservativm can reside within the customized containers.