WrapUp NeIC2015 - seeds planted
Yesterday the Nordic e-Infrastructure Collaboration Conference (NeIC2015) came to an end.
I talked about QNIBTerminal and what I am working on; connecting dots between metrics (graphite-ecosystem), logs (logstash & friends), inventory (QNIBInventory based on a GraphDB) and SLURM (cluster resource scheduler). I put it up on youtube:
Since I somehow took myself up to the challenge to limit my screen time this weekend and finished two paperback books I have started a while back, I will postpone a blog post about it until I am back in Germany.
I rather would like to push out some thought about an idea that evolved after the conversations I had. I really enjoyed the NeIC conference, even though I am not an offspring of the 'Nordics'. :) Since almost everyone in Scandinavia seems to speak perfect english (I was asked for the paper by an elderly couple during breakfast and I was wondering if there is anyone over here not speaking english), it is easy to communicate to begin with. Furthermore the collaboration either hides it's bias very good or there ain't much bias. Since I have worked in a french owned company and worked in France myself - continental Europe is different; maybe history matters or just the different sizes - who knows. But I don't want to drift into a soul-searching mission here... Bottom line: very open, unbiased discussions.
And since it's fairly small you are not drowning in crowed places, but interact with most of the attendees. Somehow the worst case scenario for my self-constraining 'keep your hands of your computer after the conference' bet is that to much like-minded people attended. Even worse, like-minded people with a slightly diverse and different background / work-environment, which provides insight and questions which I had not thought of yet. Yesterday I was joining lunch with Petar, Olli and Kenneth and we had a nice chat for two hours over lunch. Petar replanted the seed about fluentd, a log collector, which makes it easy to model the flow of information throughout the complete infrastructure.
Distributed Logstash
After this lengthy wrap-up and intro I would like to push out an idea that has formed yesterday while laying in bed, recalling the conversations.
The thing bothering me about my stack is, that it includes some places where the work is concentrated. Especially in the logstash case. If I add an additional micro-service the logs are unrefined until they reach logstash.
Talking to Petar about fluentd hooked me fairly fast to the idea that information is moving around within the system fluently. But as we stated in our lunch discussion, the information should be normalised quite close to the source, otherwise the routing within does not have the full context of the blob that has to be routed around.
To make the case a little bit clearer. Now a SLURM start-event comes along like this:
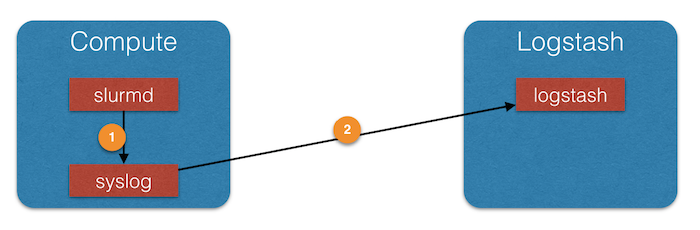
It was pushed out by slurmd and stays that stupid until it reaches logstash and it's friend to be pimped. The Job owner might be added, from where it was invoked, what nodes are involved and how those nodes are placed within the cluster, yada-yada...
{
old_msg: "slurmd slurmd: Launching batch job 10 for UID 4002",
msg: "Job 'PingPong' owned by 'Herbert' (Project: BetterWorld) started",
masternode: "compute0",
nodelist: "compute[0-4]",
slurm_jobid: 10,
time: "<some-timestamp>",
program: "slurmd"
}
That implies the message is kinda unfinished until it comes out of the logstash pipeline, in which it will be enriched with all the interesting information.
If we want to introduce something like fluentd into the mix I reckon we push the refinement where it make the most impact: as close to the source as possible. It might be a container alongside each micro-service or a group of them spread around and the closest is choosen.
Keep the config close
That would also help solving another pain point I have with my current setup. If I add a micro-service I do not want to add the configuration of how to parse the log events to a central logstash instance. I rather love to keep this configuration close to the container and let him refine his own events; or a container very close. It might be nice to have a corresponding <microservice>-logger container for each micro-service, which comes with each container.
Maybe even push the configuration into consul or etcd to have it available everywhere...
By doing so fluentd could be used in a way that it seems to be designed for. Routing messages around. If all information are at hand we are good to go.
More something like this:
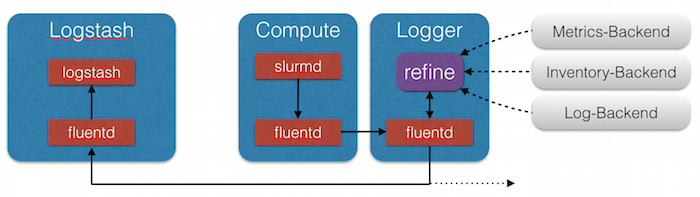
I will keep this in mind and have a look at it when I am back in Germany with some free time at hand to toy around with this idea.
If someone got some feedback feel free to ping me via mail or twitter. Or put together a blog post and point me to it; if it's written in markdown I am happy to put it alongside this post (I use jekyll).
So long, nice week-end everybody!